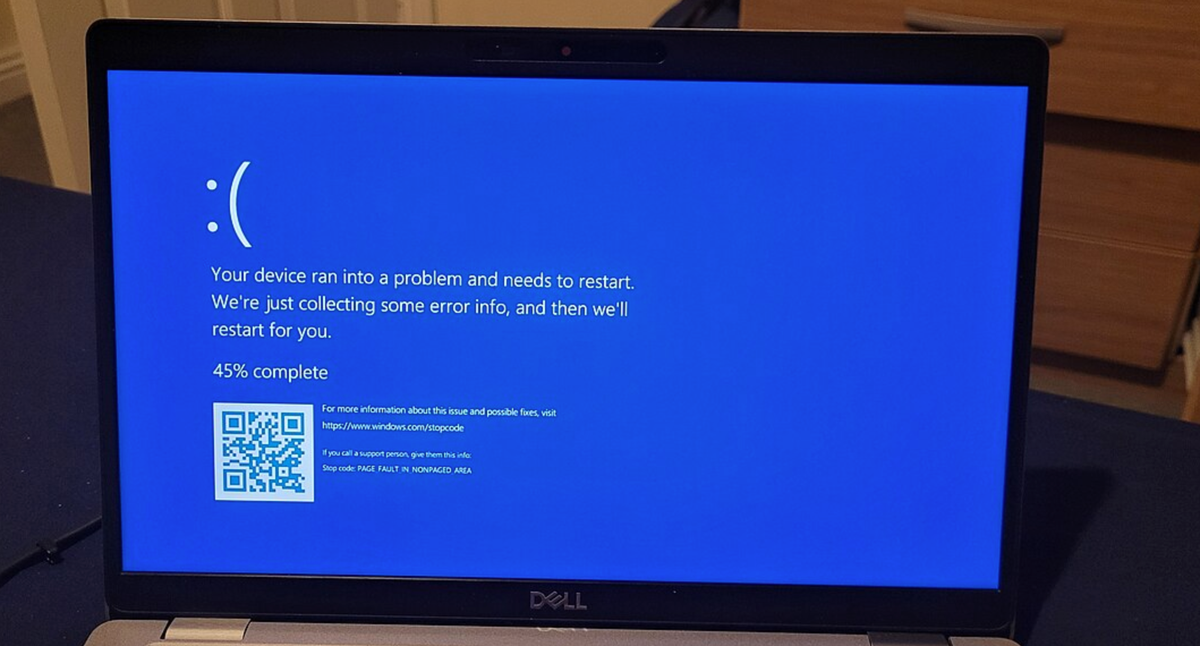
The advice, which is specifically for virtual machines using Azure, shows that sometimes the solution to a catastrophic failure is turn it off and on again. And again.
“We have received feedback from customers that several reboots (as many as 15 have been reported) may be required, but overall feedback is that reboots are an effective troubleshooting step at this stage."
So fuck the headline, the real message is: yes, rebooting is an effective troubleshooting step at the moment.
I don’t know the exact timing of that message in the timeline of the incident, so it could be early “please restart and see if issue persists” or late “something was updated, rebooting will probably help”, I don’t know.
ArsTechnica has a bit more detail. I’ll quote the important bit below.
… try to reboot affected machines over and over, which gives affected machines multiple chances to try to grab CrowdStrike’s non-broken update before the bad driver can cause the BSOD.

Paywall bypass- https://archive.is/fA4pK
Much appreciated. Now I have access to the quote:
So fuck the headline, the real message is: yes, rebooting is an effective troubleshooting step at the moment.
I don’t know the exact timing of that message in the timeline of the incident, so it could be early “please restart and see if issue persists” or late “something was updated, rebooting will probably help”, I don’t know.
ArsTechnica has a bit more detail. I’ll quote the important bit below.
https://arstechnica.com/information-technology/2024/07/crowdstrike-fixes-start-at-reboot-up-to-15-times-and-get-more-complex-from-there/
This seems like an interesting application of a “race condition”. They are hoping that the update outraces the program starting up enough to crash…