

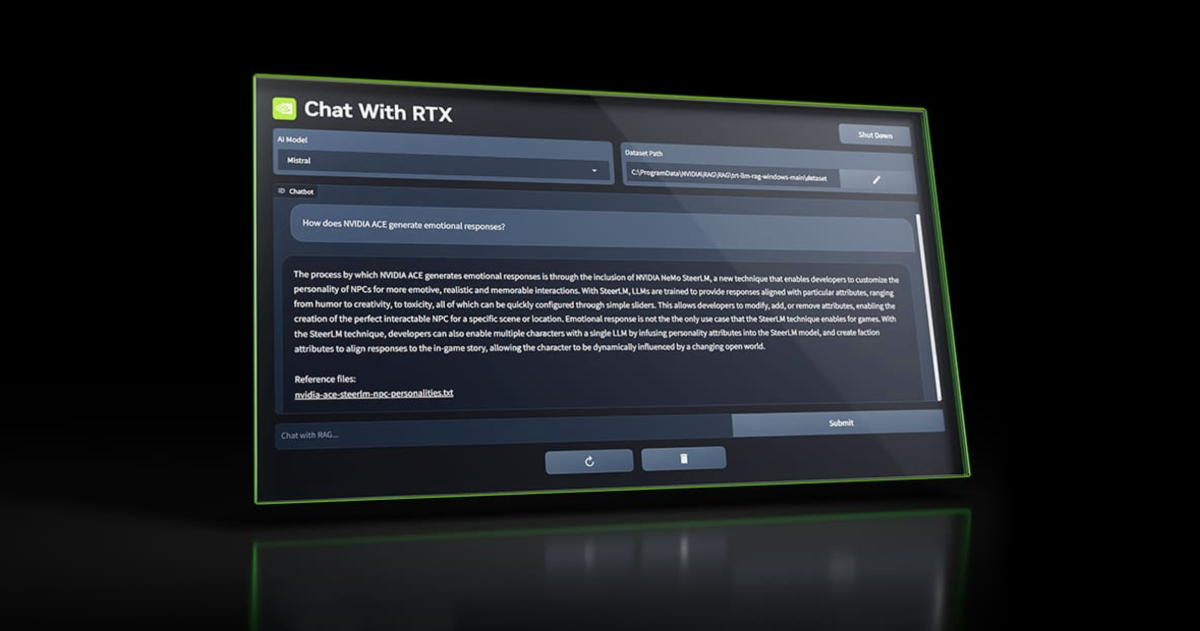
• NVIDIA released a demo version of a chatbot that runs locally on your PC, giving it access to your files and documents.
• The chatbot, called Chat with RTX, can answer queries and create summaries based on personal data fed into it.
• It supports various file formats and can integrate YouTube videos for contextual queries, making it useful for data research and analysis.
That was an annoying read. It doesn’t say what this actually is.
It’s not a new LLM. Chat with RTX is specifically software to do inference (=use LLMs) at home, while using the hardware acceleration of RTX cards. There are several projects that do this, though they might not be quite as optimized for NVIDIA’s hardware.
Go directly to NVIDIA to avoid the clickbait.
Source: https://blogs.nvidia.com/blog/chat-with-rtx-available-now/
Download page: https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/
Pretty much every LLM you can download already has CUDA support via PyTorch.
However, some of the easier to use frontends don’t use GPU acceleration because it’s a bit of a pain to configure across a wide range of hardware models and driver versions. IIRC GPT4All does not use GPU acceleration yet (might need outdated; I haven’t checked in a while).
If this makes local LLMs more accessible to people who are not familiar with setting up a CUDA development environment or Python venvs, that’s great news.
I’d hope that this uses the hardware better than Pytorch. Otherwise, why the specific hardware demands? Well, it can always be marketing.
There are several alternatives that offer 1-click installers. EG in this thread:
AGPL-3.0 license: https://jan.ai/
MIT license: https://ollama.com/
MIT license: https://gpt4all.io/index.html
(There’s more.)
Ollama with Ollama WebUI is the best combo from my experience.
Gpt4all somehow uses Gpu acceleration on my rx 6600xt
Ooh nice. Looking at the change logs, looks like they added Vulkan acceleration back in September. Probably not as good as CUDA/Metal on supported hardware though.
getting around 44 iterations/s (or whatever that means) on my gpu