

I want to be able to put in one or multiple images and have AI spit out the prompts needed in-depth to get an image like that and then use those prompts. It would be cool if it could self-test itself before giving the results to try and find the closest seed and prompt it could to generate the image.
You must log in or register to comment.
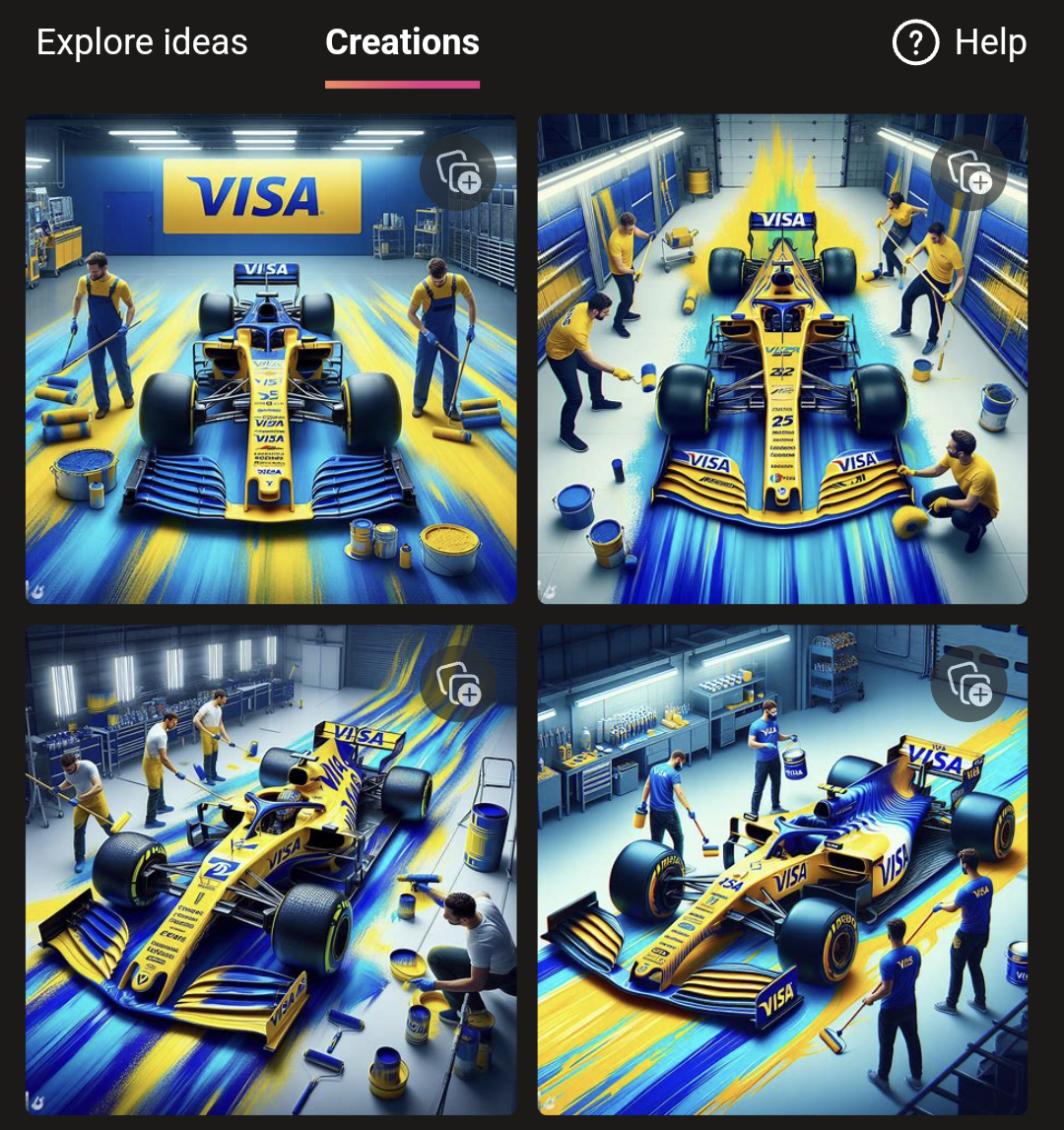
I had a go with bing copilot. I gave it this image which I generated the other day:

Then asked it “Cash you create a prompt for an image creation ai that would create images similar to this one?” and it gave me back two prompts:
Create an image of a modern Formula 1 racing car being painted by a team of artists. The car should be adorned with the branding of a major global company, and the artists should be actively painting vibrant, dynamic streaks of color onto the car that match the brand’s colors. The setting is a well-lit, professional garage with tools and equipment visible in the background.
and
“The image shows three individuals painting a Formula 1 racing car inside what appears to be a professional garage. - The racing car is prominently branded with “VISA” logos and is mainly yellow and blue, matching VISA’s brand colors. - Dynamic blue and yellow paint streaks are visible on both the floor surrounding the car and on parts of the vehicle itself, giving it an energetic appearance. - Each individual is holding a paint roller; they are in action, applying paint to different parts of the racecar. - The garage floor is white but covered in vibrant splashes of blue and yellow paint where they are working. - In the background, shelves stocked with various tools and equipment can be seen.”
Which have these images respectively:

and
deleted by creator
I love the second one down on the left. Dude is about to start hacking at the car with his fire knife.
wait try generating something with a specific person doing something theyre not known for. first person that comes to mind is jeff buckley and thing is archery. i want to see if it can identify more than just an action and vibe without being informed. if so, that means it had facial identification software built in.
deleted by creator
Not as good as you require but Chat GPT 4 when asked right will give you prompts you can use to make the image. I find I get better results by asking for it to describe the image in great detail and then making adjustments where it clearly didn’t understand the image right.
I’ve even had luck asking one AI to help me with prompts for another AI, then telling it what went wrong, and it helping me to make adjustments.
Midjourney has the /describe command or something similar that does just this. You link an image and it spits back the prompt that would get you close to that image.
GPT4-Vision can do it, sort of. It doesn’t have a particularly great understanding of what’s going on in a scene, but it can be used for some interesting stuff. I posted a link a few weeks back to an example from DALL-E Party, which hooks up an image generator and an image describer in a loop: https://kbin.social/m/imageai@sh.itjust.works/t/661021/Paperclip-Maximizer-Dall-E-3-GPT4-Vision-loop-see-comment
merde posted a link in the comments there to the goatpocalypse example – https://dalle.party/?party=vCwYT8Em – which is even more fun.
IIRC, A1111 has an extension to interrogate. I think it does BLIP or CLIP or Deepdanbooru. It can do batch and write out to a text file per image.
Spoiler: >!None of them are very good.!<


