
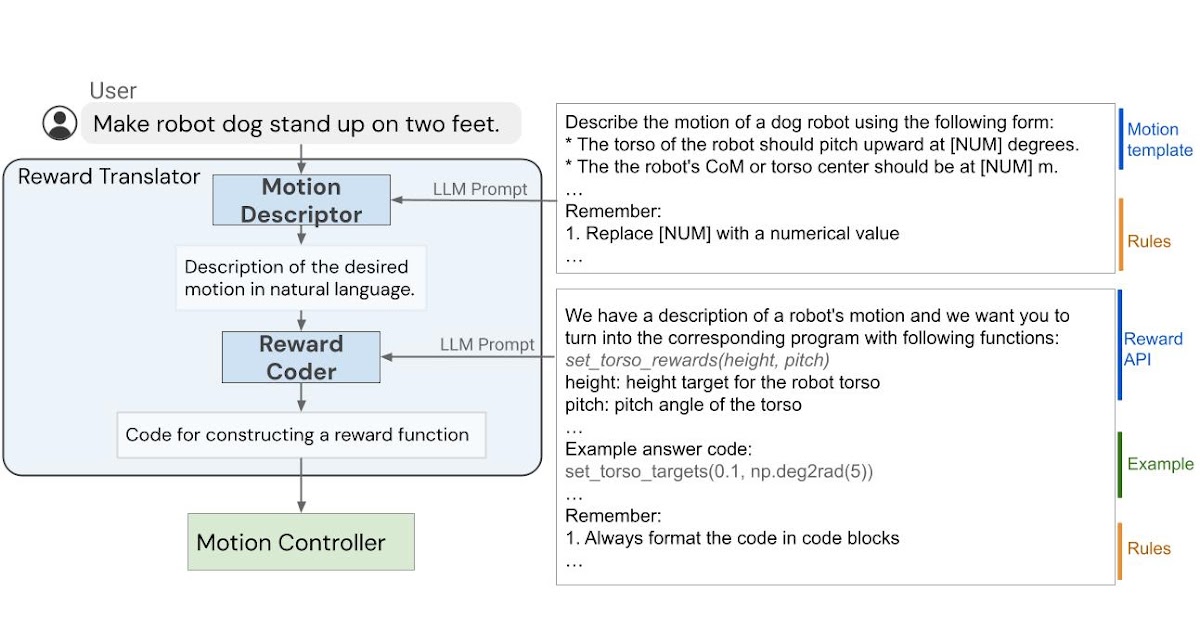
In “Language to Rewards for Robotic Skill Synthesis”, we propose an approach to enable users to teach robots novel actions through natural language input. To do so, we leverage reward functions as an interface that bridges the gap between language and low-level robot actions. We posit that reward functions provide an ideal interface for such tasks given their richness in semantics, modularity, and interpretability. They also provide a direct connection to low-level policies through black-box optimization or reinforcement learning (RL). We developed a language-to-reward system that leverages LLMs to translate natural language user instructions into reward-specifying code and then applies MuJoCo MPC to find optimal low-level robot actions that maximize the generated reward function. We demonstrate our language-to-reward system on a variety of robotic control tasks in simulation using a quadruped robot and a dexterous manipulator robot. We further validate our method on a physical robot manipulator.